Fat Chance: Writing about Probability
Posted by Armando Brito Mendes | Filed under Data Science, estatística

Bons conselhos sobre como comunicar incerteza, probabilidades e percentagens
Since the COVID-19 pandemic began, almost every choice we have made in our day-to-day lives has required careful consideration of the odds. How dangerous is going to the supermarket at peak time? Is it safe to see friends after getting one vaccine shot? Will children get sick, or spread the virus to others, if they go back to school?
Just the quantity of decisions can be exhausting. But there’s something else making all of these choices so difficult: People, by and large, are bad at probability. We turn high odds into certainties, as when people assume that the accuracy of PCR tests for COVID means they’ll always yield correct results, or when we think of relatively unlikely events, like catching the virus after being fully vaccinated, as impossible. And in between 100 percent certainty and zero chance, the way we interpret any given number can change radically based on how that probability is expressed.
Such glitches in thinking aren’t surprising, says journalist and statistician Regina Nuzzo, a professor of statistics at Gallaudet University in Washington, DC, and a senior advisor for statistics communication and media innovation at the American Statistical Association. “Human brains hate probability, they hate ambiguity, they hate the uncertainty,” she says. “We’re just not wired to deal with this sort of thing very well.”
But for science writers, avoiding uncertainty isn’t an option. “Everything [in science] is quantified by the likelihood or lack of likelihood of it happening,” says science journalist Tara Haelle, who has written extensively about covering statistics for the Association of Health Care Journalists (AHCJ). But as Haelle says, “Humans don’t make decisions that way.” People tend to be far more comfortable with a definitive yes or no, she says, than with the uncharted space in between.
That means science writers have to work hard to coax readers away from those two extremes and toward a more nuanced understanding. “Probability information is crucial to making a really informed decision,” says psychologist Vivianne Visschers, who studies risk communication and decision making at the University of Applied Sciences and Arts Northwestern Switzerland. Without a good understanding of such information, readers may ease up on pandemic social-distancing precautions too early, or avoid a medical examination that they want to have.
There’s no single, straightforward way to write about probability. The very concept can be ambiguous and tricky. But strategies like using analogies, creating visuals, and making careful use of language can help to convey just what a 15 percent chance of an extreme weather event, or an 80 percent chance of recovering from a disease, really means.
Tags: comunicação em ciência, probabilidades
Seeing How Much We Ate Over the Years
Posted by Armando Brito Mendes | Filed under Data Science, data sets, visualização

Um excelente relatório sobre o q os americanos têm vindo a comer desde q há registos. Gráficos excelentes.
The United States Department of Agriculture keeps track of food availability for over 200 items, which can be used to estimate food consumption at the national level. They have data for 1970 through 2019, so we can for example, see how much beef Americans consume per year on average and how that has changed over four decades.
So that’s what I did.
How long will chicken reign supreme? Who wins between lemon and lime? Is nonfat ice cream really ice cream? Does grapefruit ever make a comeback? Find out in the charts below.
The rankings are broken into six main food groups: proteins, vegetables, fruits, dairy, grains, and added fats.
Tags: alimentação, area charts, food
Why Am I Numb To The Numbers?
Posted by Armando Brito Mendes | Filed under Data Science, data sets, estatística, visualização
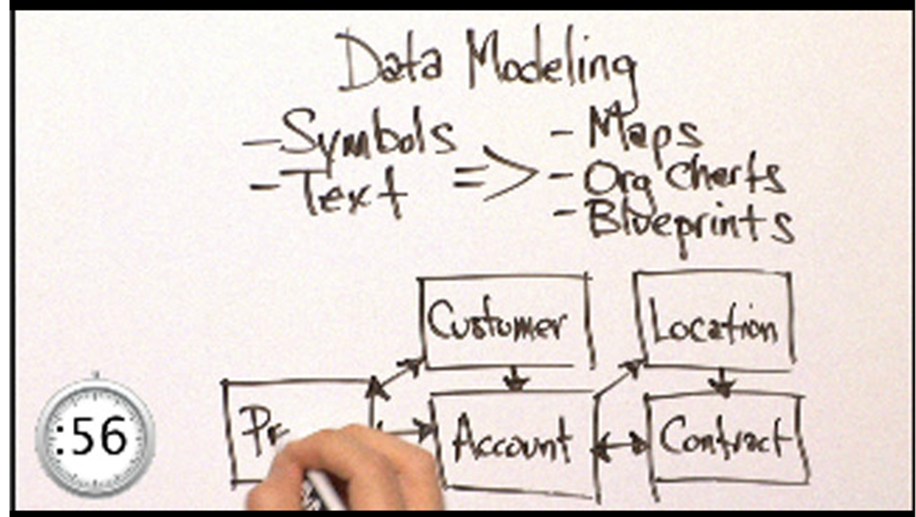
Sobre a dormência causada pelos grandes números.
COMIC: For My Job, I Check Death Tolls From COVID. Why Am I Numb To The Numbers?
April 25, 20218:16 AM ET
Each week I check the latest deaths from COVID-19 for NPR. After a while, I didn’t feel any sorrow at the numbers. I just felt numb. I wanted to understand why — and how to overcome that numbness.
Tags: Banda Desenhada, big number dumb, psicologia
10 Guidelines for DataViz Accessibility
Posted by Armando Brito Mendes | Filed under Data Science, materiais para profissionais, visualização
10 regras para construir representações de dados mais inclusivas
Introduction
In a world that surrounds us with information at all times, data visualization is increasingly more popular, as a tool to help us make sense of the information, and to grab the attention of users and readers. This has significant implications for the overall accessibility of data. In this article we are exploring the accessibility problems of data visualizations, and how to start solving them.
What is data visualization meant to do?
Before we dive into the accessibility implications of data visualizations, it is useful to consider the value they are meant to provide to the user. This will help us think about how to provide value to all users – including users with various disabilities.
Tags: acessibilidade, dataviz
Plot for D3 Users
Posted by Armando Brito Mendes | Filed under Data Science, visualização
Uma novo biblioteca javaScript para gráficos e comparação com D3
D3 is how I learned JavaScript, and it’s the only chart library I know well. I’m familiar with the idea of things like Vega-Lite, ggplot, and matplotlib, but I’ve never really used them; I’m a monoglot.
But D3 can be hard to learn, and a slow way to make a quick chart. I like to paraphrase Amanda Cox saying, “You should use D3 if you think it’s perfectly normal to have to write a hundred lines of code to get a bar chart.” Over the last ten years there have been many attempts to address this by building libraries on top of D3, but I’ve never gotten into any of them.
Plot, announced today, is the first thing that’s gotten through to me. Granted, if you wanna get all conspiratorial, I suppose they’re paying me to use it for work — but over the last couple months, when I start a personal project and want a chart, I’ve started reaching first for Plot.
Tags: gráficos, java script
OpenML Data
Posted by Armando Brito Mendes | Filed under Data Science, data sets

Bom site com muitos dados para Aprendizagem
Only showing active (verified) datasets.
3239 results
credit-g (1) This dataset classifies people described by a set of attributes as good or bad credit risks. This dataset comes with a cost matrix: “` Good Bad (predicted) Good 0 1 (actual) Bad 5 0 “` It is worse… 505934 runs19 likes239 downloads258 reach28 impact
1000 instances – 21 features – 2 classes – 0 missing values
blood-transfusion-service-center (1) Data taken from the Blood Transfusion Service Center in Hsin-Chu City in Taiwan — this is a classification problem. To demonstrate the RFMTC marketing model (a modified version of RFM), this study… 467766 runs5 likes86 downloads91 reach41 impact
748 instances – 5 features – 2 classes – 0 missing values
monks-problems-2 (1) Once upon a time, in July 1991, the monks of Corsendonk Priory were faced with a school held in their priory, namely the 2nd European Summer School on Machine Learning. After listening more than one… 394293 runs2 likes27 downloads29 reach37 impact
601 instances – 7 features – 2 classes – 0 missing val
DS Beginners Guide
Posted by Armando Brito Mendes | Filed under Data Science

Muitos links com informação relevante para Data Science
Quick Start Concepts
Projects
Introductory Concepts
- Introduction to data mining techniques
- Supervised and Unsupervised learning algorithms
- Difference between classification and Prediction techniques
- Classification and Clustering Algorithms
- Feature selection techniques in R
- How to handle imbalanced datasets in machine learning
….
Tags: data mining, ML, models, Python, R