Machine Learning MOOC
Posted by Armando Brito Mendes | Filed under estatística, materiais ensino, videos
Um curso muito completo de machine learning
About the Course
Machine learning is the science of getting computers to act without being explicitly programmed. In the past decade, machine learning has given us self-driving cars, practical speech recognition, effective web search, and a vastly improved understanding of the human genome. Machine learning is so pervasive today that you probably use it dozens of times a day without knowing it. Many researchers also think it is the best way to make progress towards human-level AI. In this class, you will learn about the most effective machine learning techniques, and gain practice implementing them and getting them to work for yourself. More importantly, you’ll learn about not only the theoretical underpinnings of learning, but also gain the practical know-how needed to quickly and powerfully apply these techniques to new problems. Finally, you’ll learn about some of Silicon Valley’s best practices in innovation as it pertains to machine learning and AI.
This course provides a broad introduction to machine learning, datamining, and statistical pattern recognition. Topics include: (i) Supervised learning (parametric/non-parametric algorithms, support vector machines, kernels, neural networks). (ii) Unsupervised learning (clustering, dimensionality reduction, recommender systems, deep learning). (iii) Best practices in machine learning (bias/variance theory; innovation process in machine learning and AI). The course will also draw from numerous case studies and applications, so that you’ll also learn how to apply learning algorithms to building smart robots (perception, control), text understanding (web search, anti-spam), computer vision, medical informatics, audio, database mining, and other areas.
FAQ
- What is the format of the class?The class will consist of lecture videos, which are broken into small chunks, usually between eight and twelve minutes each. Some of these may contain integrated quiz questions. There will also be standalone quizzes that are not part of video lectures, and programming assignments.
- How much programming background is needed for the course?The course includes programming assignments and some programming background will be helpful.
- Do I need to buy a textbook for the course?No, it is self-contained.
- Will I get a statement of accomplishment after completing this class?Yes. Students who successfully complete the class will receive a statement of accomplishment signed by the instructor.
Tags: big data, bioinformatica, captura de conhecimento, data mining, DW \ BI
LIBSVM — A Library for Support Vector Machines
Posted by Armando Brito Mendes | Filed under software
Página dos autores da biblioteca LIBSVM, a mais usada para SVM
LIBSVM — A Library for Support Vector Machines
Chih-Chung Chang and Chih-Jen Lin
 Version 3.17 released on April Fools’ day, 2013. We slightly adjust the way class labels are handled internally. By default labels are ordered by their first occurrence in the training set. Hence for a set with -1/+1 labels, if -1 appears first, then internally -1 becomes +1. This has caused confusion. Now for data with -1/+1 labels, we specifically ensure that internally the binary SVM has positive data corresponding to the +1 instances. For developers, see changes in the subrouting svm_group_classes of svm.cpp.
Version 3.17 released on April Fools’ day, 2013. We slightly adjust the way class labels are handled internally. By default labels are ordered by their first occurrence in the training set. Hence for a set with -1/+1 labels, if -1 appears first, then internally -1 becomes +1. This has caused confusion. Now for data with -1/+1 labels, we specifically ensure that internally the binary SVM has positive data corresponding to the +1 instances. For developers, see changes in the subrouting svm_group_classes of svm.cpp.
We now have a nice page LIBSVM data sets providing problems in LIBSVM format.
A practical guide to SVM classification is available now! (mainly written for beginners)
LIBSVM tools available now!
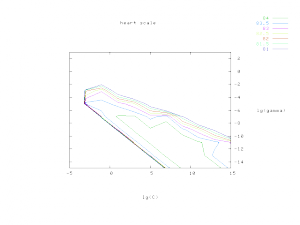
We now have an easy script (easy.py) for users who know NOTHING about svm. It makes everything automatic–from data scaling to parameter selection.
The parameter selection tool grid.py generates the following contour of cross-validation accuracy. To use this tool, you also need to install python and gnuplot.
Tags: captura de conhecimento, data mining, otimização, R-software, RapidMiner, WEKA
Cross-validation in RapidMiner
Posted by Armando Brito Mendes | Filed under software

Explica como utilizar a validação cruzada no RapidMiner
Cross-validation is a standard statistical method to estimate the generalization error of a predictive model. In 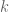

This post explains how to interpret cross-validation results in RapidMiner.
Tags: captura de conhecimento, data mining, RapidMiner
wekalist – resposta a questões
Posted by Armando Brito Mendes | Filed under software

Um fórum de discussão sobre os algoritmos do WEKA
WEKA
WEKA machine learning software discussion
Tags: captura de conhecimento, data mining, WEKA
Presentation Graphs
Posted by Armando Brito Mendes | Filed under estatística, materiais para profissionais, visualização
Bons conselhos para a escolha de gráficos
Presentation graphs are key to effective visualisation, and can demonstrate data in a really engaging way. But with so many graphs to choose from, how do presenters know which one to choose? And how can they make the most of basic graphs to create engaging, truly visual slides?
Allow us to present the m62 guide to presentation graphs. We talk about the different types of graphs, and how best to use them in different situations. All of the graphs listed below can be produced quickly and easily with Microsoft PowerPoint live charts (Insert tab > Chart), but combining these with animation and other PowerPoint tools can produce even more effective graphs that will really engage your audience.
Tags: belo, captura de conhecimento, data mining, Estat Descritiva
visual exploration of US gun murders
Posted by Armando Brito Mendes | Filed under estatística, visualização
Uma visualização animada muito dramática
Information visualization firm Periscopic just published a thoughtful interactive piece on gun murders in the United States, in 2010. It starts with the individuals: when they were killed, coupled with the years they potentially lost. Each arc represents a person, with lived years in orange and the difference in potential years in white. A mouseover on each arc shows more details about that person.
You can then select categories and demographics, which provide comparisons between ethnicities, gun type, sex, and others. Roll over the bar in the middle for a density plot representation.
Finally, specific breakouts on the bottom provide notables in the data and what they mean.
There are many routes that you could take with this data. At its core, it’s a multivariate dataset with many observations over an entire year. But Periscopic pays close attention to the context and the sensitivity of the data. They make the data relatable while also providing a view of the big picture—without stripping away what the data means. See it live here.
Tags: análise de dados, belo, captura de conhecimento, data mining, Estat Descritiva
FlowingData Tutorials
Posted by Armando Brito Mendes | Filed under estatística, visualização
Excelentes tutoriais sobre visualizações de dados.
How to Animate Transitions Between Multiple Charts
Getting Started with Charts in R
How to Make an Interactive Choropleth Map ☆
More on Making Heat Maps in R ☆
Mapping with Diffusion-based Cartograms ☆
How to Make an Interactive Network Visualization
A Variety of Area Charts with R ☆
How to Draw in R and Make Custom Plots ☆
How to Visualize and Compare Distributions
How to Make a Sankey Diagram to Show Flow ☆
Interactive Time Series Chart with Filters ☆
Calendar Heatmaps to Visualize Time Series Data ☆
How to Hand Edit R Plots in Inkscape ☆
How to Make a Contour Map ☆
Using Color Scales and Palettes in R ☆
Build Interactive Time Series Charts with Filters ☆
How to map connections with great circles
How to Make Bubble Charts
How to visualize data with cartoonish faces ala Chernoff
How to: make a scatterplot with a smooth fitted line
An Easy Way to Make a Treemap
How to Make a Heatmap – a Quick and Easy Solution
How to Make an Interactive Area Graph with Flare
How to Make a US County Thematic Map Using Free Tools
How to Make a Graph in Adobe Illustrator
How to Make Your Own Twitter Bot – Python Implementation
Grabbing Weather Underground Data with BeautifulSoup
Tags: análise de dados, captura de conhecimento, data mining, desnvolvimento de software, Estat Descritiva, R-software
Five years of traffic fatalities
Posted by Armando Brito Mendes | Filed under estatística, visualização

Exemplo de mapa tipo "tapete" para dados cronológicos e geográficos
. John Nelson extended on that, pulling five years of data and subsetting by some factors: alcohol, weather, and if a pedestrian was involved. And he aggregated by time of day and day of week instead of calendar dates.
For example, the above is the breakdown of accidents that involved alcohol. As you might expect, there’s a higher count of traffic fatalities during the weekend and late night hours since people don’t have to work the next day. Or you can see when weather is a factor:
Tags: captura de conhecimento, data mining, Estat Descritiva, SIG
Handbook of Statistical Analysis and Data Mining Applications
Posted by Armando Brito Mendes | Filed under estatística, materiais ensino, visualização

Livro completo no google books com as ligações entre a estatística e o DM
Índice
| 1 | |
| 119 | |
| 363 | |
| 705 | |
| 789 | |
| 801 | |
| 823 | |
Tags: captura de conhecimento, data mining, text mining
Data Mining for Business Intelligence
Posted by Armando Brito Mendes | Filed under materiais ensino, SAD - DSS

Livro completo no google books com boa introdução ao data mining
Índice
Tags: captura de conhecimento, data mining, Excel, programação em folha de cálculo, software estatístico