An Introduction to Word Embeddings
Posted by Armando Brito Mendes | Filed under Sem categoria
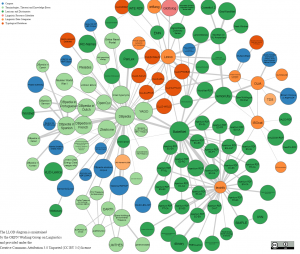
bom texto sobre uma técnica em NLP – Natural Language Pocessing
Part 1: Applications
Written by Aaron Geelon So
If you already have a solid understanding of word embeddings and are well into your data science career, skip ahead to the next part!
Human language is unreasonably effective at describing how we relate to the world. With a few, short words, we can convey many ideas and actions with little ambiguity. Well, mostly.
Because we’re capable of seeing and describing so much complexity, a lot of structure is implicitly encoded into our language. It is no easy task for a computer (or a human, for that matter) to learn natural language, for it entails understanding how we humans observe the world, if not understanding how to observe the world.
For the most part, computers can’t understand natural language. Our programs are still line-by-line instructions telling a computer what to do — they often miss nuance and context. How can you explain sarcasm to a machine?
There’s good news though. There’s been some important breakthroughs in natural language processing (NLP), the domain where researchers try to teach computers human language.
Tags: data mining, machine learning, text mining
imagens criadas por campos vetoriais
Posted by Armando Brito Mendes | Filed under materiais ensino, software, visualização

This website allows you to explore vector fields in real time.
“Vector field” is just a fancy way of saying that each point on a screen has some vector associated with it. This vector could mean anything, but for our purposes we consider it to be a velocity vector.
Now that we have velocity vectors at every single point, let’s drop thousands of small particles and see how they move. Resulting visualization could be used by scientist to study vector fields, or by artist to get inspiration!
Learn more about this project on GitHub
Stay tuned for updates on Twitter.
With passion,
Anvaka
Tags: belo
Free Hadoop Tutorial: Master BigData
Posted by Armando Brito Mendes | Filed under lições, materiais ensino, software
clique na imagem para seguir o link
BigData is the latest buzzword in the IT Industry. Apache’s Hadoop is a leading Big Data platform used by IT giants Yahoo, Facebook & Google. This course is geared to make a Hadoop Expert.
What should I know?
This is an absolute beginner guide to Hadoop. But knowledge of 1) Java 2) Linux will help
Syllabus
| Tutorial | Introduction to BIG DATA: Types, Characteristics & Benefits |
| Tutorial | Hadoop Tutorial: Features, Components, Cluster & Topology |
| Tutorial | Hadoop Setup Tutorial – Installation & Configuration |
| Tutorial | HDFS Tutorial: Read & Write Commands using Java API |
| Tutorial | What is MapReduce? How it Works – Hadoop MapReduce Tutorial |
| Tutorial | Hadoop & Mapreduce Examples: Create your First Program |
| Tutorial | Hadoop MapReduce Tutorial: Counters & Joins with Example |
| Tutorial | What is Sqoop? What is FLUME – Hadoop Tutorial |
| Tutorial | Sqoop vs Flume vs HDFS in Hadoop |
| Tutorial | Create Your First FLUME Program – Beginner’s Tutorial |
| Tutorial | Hadoop PIG Tutorial: Introduction, Installation & Example |
| Tutorial | Learn OOZIE in 5 Minutes – Hadoop Tutorial |
| Tutorial | Big Data Testing: Functional & Performance |
| Tutorial | Hadoop & MapReduce Interview Questions & Answers |
Tags: big data
Pianogram
Posted by Armando Brito Mendes | Filed under estatística, visualização
clicar na imagem para seguir o link
Uma visualização em gráfico de barras das notas de canções
Pianogram
This is what you get when you cross a histogram and piano keys to show note distribution of songs. It’s the pianogram. View examples such as Fur Elise or the classic Chopsticks, or punch in your own MIDI-formatted song for a taste of the distribution ivories.
Here’s the distribution for Kenny Loggins’ Danger Zone.
Because why not.
Tags: belo
working with alien SPSS files
Posted by Armando Brito Mendes | Filed under data sets, estatística, materiais ensino
clique no ícon para seguir o link
Informação sobre diversos inquéritos e acesso aos dados respetivos
Close Encounters of the Fourth Kind: working with alien SPSS files
[New page 23 Oct 2014: last updated 5 June 2017]
[NB: Notes and commentaries below may arrive as pdf files in your download folder]
Close Encounters of the Fourth Kind: working with alien SPSS files (pdf)
An alternative working title would have been: Sows’ Ears and Silk Purses: working with other peoples’ SPSS files as a follow-up to Old Dog, Old Tricks, my 2006 presentation to ASSESS. Thought about using Old Dog, New Tricks, but it doesn’t carry the same sense of horror and fun.
Slide-shows covered recent work on other people’s files, including a live demo of Jon Peck’s Python code to move question numbers from the end to the beginning of variable labels and to change labels from UPPER to Mixed case text. Also included were some new tricks and demos of things I didn’t know SPSS would do until I tried. I haven’t used PowerPoint since York 2006, but I found [Alt][PrintScreen] and MS Snip incredibly useful for getting screenshots into Word, and they also copied easily into Ppt. The presentation ran SPSS live, drawing on my explorations of:
British Social Attitudes
Commentary on SPSS file for British Social Attitudes 2011 (pdf)
Notes on British Social Attitudes 2004 teaching data set (pdf) as used by Marsh and Elliott, 2008
(See also page British Social Attitudes which has links to later commentaries on the ease of use and understanding of SPSS saved files distributed by UKDS on page British Social Attitudes: Exploring the SPSS files and detailed accounts of my creation in 2016 of a cumulative mother fille for all waves 1983 to 2014 on page British Social Attitudes 1983 to 2014: Cumulative SPSS file
Understanding Society
Commentary on Understanding Society 2010 (pdf)
NORC General Social Survey (GSS)
As of March 2016, the NORC GSS website has been completely revamped and is easier to navigate. Some of the content in the following commentaries may now be otiose.
Commentary on full NORC General Social Survey 2008 (pdf)
Commentary on subset of General Social Survey 2008 (pdf) (as used by Sweet & Grace-Martin)
Commentary on GSS 2008 SPSS files for Babbie et al (pdf) (as used by Babbie, Halley, Wagner & Zaino)
(UK) ONS National Well-being
[New page 2 May 2015]
ONS National Well-being
Commentary on Unrestricted Access Teaching Dataset (ONS Opinions Survey, Well‐Being Module (pdf)
Data set and user guide from the Cathie Marsh Centre for Census and Survey Research, Manchester now renamed the Cathie Marsh Institute for Social Research, . This dataset (SN7146) contains a selection of variables from the April 2011 wave of the ONS Opinions Survey, Well-Being Module, April – August 2011 (SN 6893) which in turn is part of the regular government survey Opinions and Lifestyle Survey, run in various guises since 1990
Tags: IBM SPSS Statistics, inquéritos
British Social Attitudes
Posted by Armando Brito Mendes | Filed under data sets, estatística, materiais ensino
clique no ícon para seguir o link
Inquerito e dados respetivos sobre atitudes sociais no UK
British Social Attitudes 1983 onwards
Cumulative SPSS file
[New page 22 June 2016: last updated 14 Feb 2017]
Cumulative files 1983 onwards
Attempting analyses across waves became increasingly frustrating as I encountered a range of anomalies, incompatibilities and inconsistencies, not to mention universally incomplete and/or incorrect specifications of measurement levels, missing values and value labels. Accordingly I set myself the task of generating a complete cumulative SPSS file containing the data from all waves from 1983 to 2014 (one colleague described this undertaking as Herculean) to provide what will hopefully be a valuable resource for teachers, students and researchers. The 2015 wave was added in January 2017.
Index to UKDS downloads for British Social Attitudes 1983 – 2014 is an Excel file detailing, for each wave 1983 – 2014, year of survey, link to UKDS, download filename, size of file, number of cases, number of variables, number of variables with non-numeric formats and the new working filename assigned to amended files. The amended *.sav files were sent to Natcen for approval and possible deposit with UKDS, but are now superseded.
Non-numeric variables in British Social Attitudes is a step-by-step account of identifying, in each wave, variables with the same name, but different formats. Several of these variables are specified as Strings with widths varying from A4 to A60, but some are in fact numbers. Others are dates or times in DATE or TIME format and one is in COMMA1. These and other factors prevent merging data from different waves using the SPSS command ADD FILES. It’s been quite complex and tedious tracking them all down, but I eventually managed to create cumulative files for 1983 – 1994 and 2011 – 2014. Merging 1995 – 2005 and 2006 – 2009 was more daunting, as several problems remained to be resolved, but I eventually managed to generate a draft cumulative file for the whole series. Much more meticulous and painstaking detective work and editing was required before a beta version was ready for public release.
Cumulative SPSS file 1983 to 2014
This task was completed on 20 June 2016 and the pass-word protected “mother” file (0.99 gb) has now been lodged (via Dropbox) with Natcen and UKDS for approval and distribution. Custom-written Python code, freely and generously supplied by Jon Peck (retired Senior Software Engineer, IBM-SPSS) has saved me weeks if not months of painstaking needle-in-haystack searches. I also wish to thank Dr Chris Stride (Sheffield) who suggested using the sort facility in Excel to separate variable names with single (positive) missing values from those with paired (positive and equivalent negative) missing values.
For sure, some mini-glitches may remain, but to find and resolve these would at this stage be completely uneconomic of my time. However users are warned that, because metadata for repeated variables are taken from the most recent wave, the value labels for categories of some variables differ from those of earlier waves. This is particularly true of ordinal variables for income groups.
Tags: IBM SPSS Statistics, inquéritos
SSRC Survey Unit Quality of Life
Posted by Armando Brito Mendes | Filed under estatística, materiais ensino
clique no ícon para seguir o link
Dados e descrição de um inquérito sobre qualidade de vida no UK
The abstracts contain details of content, sampling, fieldwork and available data files. The questionnaires are facsimiles of the actual questionnaires used in the field. The user manuals contain questionnaires, unweighted frequency counts on the raw data as well as technical information on fieldwork, sampling, coding, show-cards and interviewer instructions. The SPSS saved files are restorations from original files generated in the 1970s with some editing of SPSS setup files from 1970s versions to SPSS for Windows (11, 15, 18 and 19): a few (self-explanatory) derived variables have been left in.
Quality of Life in Britain: 1st Pilot Survey, March 1971
1: Abstract
2: Questionnaire
3: User Manual
4: SPSS saved file for 1st pilot
Quality of Life in Britain: 2nd Pilot Survey, Oct-Nov 1971
1: Abstract
2: Questionnaire
3: User Manual
4: SPSS saved file for 2nd pilot
Quality of Life in Britain: 1st National Survey 1973
(replicated simultaneously in Stoke-on-Trent and Sunderland)
1: Abstract
2: Questionnaire
3: User Manual for main GB survey
4a: SPSS saved file for main GB survey 1973
4b: SPSS saved file for Stoke-on-Trent survey 1973
4c: SPSS saved file for Sunderland survey 1973
Quality of Life in Britain: 2nd National Survey 1975
1: Abstract
2: Questionnaire
3: User Manual
4: SPSS saved file for main GB survey 1975
Tags: IBM SPSS Statistics, inquéritos
An Introduction to Implementing Neural Networks using TensorFlow
Posted by Armando Brito Mendes | Filed under materiais ensino, software

clicar na imagem para seguir o link
Uma boa introdução ao tensor flow e deep learning
Introduction
If you have been following Data Science / Machine Learning, you just can’t miss the buzz around Deep Learning and Neural Networks. Organizations are looking for people with Deep Learning skills wherever they can. From running competitions to open sourcing projects and paying big bonuses, people are trying every possible thing to tap into this limited pool of talent. Self driving engineers are being hunted by the big guns in automobile industry, as the industry stands on the brink of biggest disruption it faced in last few decades!
If you are excited by the prospects deep learning has to offer, but have not started your journey yet – I am here to enable it. Starting with this article, I will write a series of articles on deep learning covering the popular Deep Learning libraries and their hands-on implementation.
In this article, I will introduce TensorFlow to you. After reading this article you will be able to understand application of neural networks and use TensorFlow to solve a real life problem. This article will require you to know the basics of neural networks and have familiarity with programming. Although the code in this article is in python, I have focused on the concepts and stayed as language-agnostic as possible.
Let’s get started!
Table of Contents
- When to apply neural nets?
- General way to solve problems with Neural Networks
- Understanding Image data and popular libraries to solve it
- What is TensorFlow?
- A typical “flow” of TensorFlow
- Implementing MLP in TensorFlow
- Limitations of TensorFlow
- TensorFlow vs. other libraries
- Where to go from here?
Tags: big data, data mining, machine learning, text mining
British Social Attitudes
Posted by Armando Brito Mendes | Filed under data sets, estatística, materiais ensino
clique no ícon para seguir o link
Dados de um inquérito britânico sobre atitudes sociais
The British Social Attitudes survey is the leading social research survey in Britain. Since 1983, the annual surveys
conducted by the National Centre for Social Research (Natcen) have continually monitored and interpreted the British public’s changing attitudes towards social, economic, political and moral issues. Its findings are reported
and interpreted in a series of annual reports.
The British Social Attitudes Information System is maintained by the Centre for Comparative European
Survey Data (CCESD) to provide non-specialist users with on-line access and analysis of a cumulative database of over 20,000 survey questions asked in British Social Attitudes surveys over the last 25 years.
Data and documentation from all surveys from 1983 are routinely deposited with the UK Data Service (UKDS) based at Essex University and can be searched on their page British Social Attitudes Survey . Files are accessible from UKDS: the list of currently available waves is on British Social Attitudes links 1983 onwards. I am currently working on tutorials using data from the 2011 wave and from the 2009 to 2014 waves in the cumulative file. Some of these are already available on page 3.2 Three (or more) variables and in 4.2.1 Income differences – Statistical significance
Tags: IBM SPSS Statistics, inquéritos
Data sets used in Survey Analysis
Posted by Armando Brito Mendes | Filed under data sets, estatística, materiais ensino
clique no ícon para seguir o link
mais dados de inquéritos diversos no UK
Raw data sets are exactly as they would arrive from the fieldwork agency or from institutional data-prep services (in 80-column ASCII format, fixed width font).
SPSS saved files for British Social Attitudes 1986 and 1989 and Quality of Life in Britain are initial files only. Variables in the BSA series are (re-) named using the positional naming convention. There are no mnemonic names and no derived variables, but these will be generated during the exercises. These files have full permissions for use and distribution.
SPSS (19, 21 and 22) can open *.sav and *.sps files downloaded from this site and also save them to a drive on your computer. Earlier tutorials and exercises require you to define a few variables, read in raw data and add dictionary information, then save the files. However, for surveys with dozens, if not hundreds, of variables, this would be too onerous a requirement, especially for beginners. Later tutorials and exercises will need access to much larger saved files containing hundreds of variables and thousands of cases.
Tags: IBM SPSS Statistics, inquéritos